Được coi là một công cụ mạnh mẽ để thu thập thông tin từ Internet, web scraping không chỉ hỗ trợ nhanh chóng tìm kiếm dữ liệu mà còn mang lại nhiều ứng dụng quan trọng trong lĩnh vực kinh doanh, nghiên cứu, và phân tích thị trường. Tuy nhiên, sức mạnh của web scraping cũng đồng thời mở ra những vấn đề đáng chú ý, đặc biệt là với những hình thức web scraping độc hại. Những kỹ thuật này không chỉ vi phạm các nguyên tắc đạo đức mà còn có thể gây hậu quả nghiêm trọng đối với cộng đồng trực tuyến và các doanh nghiệp.
Web Scraping là gì?
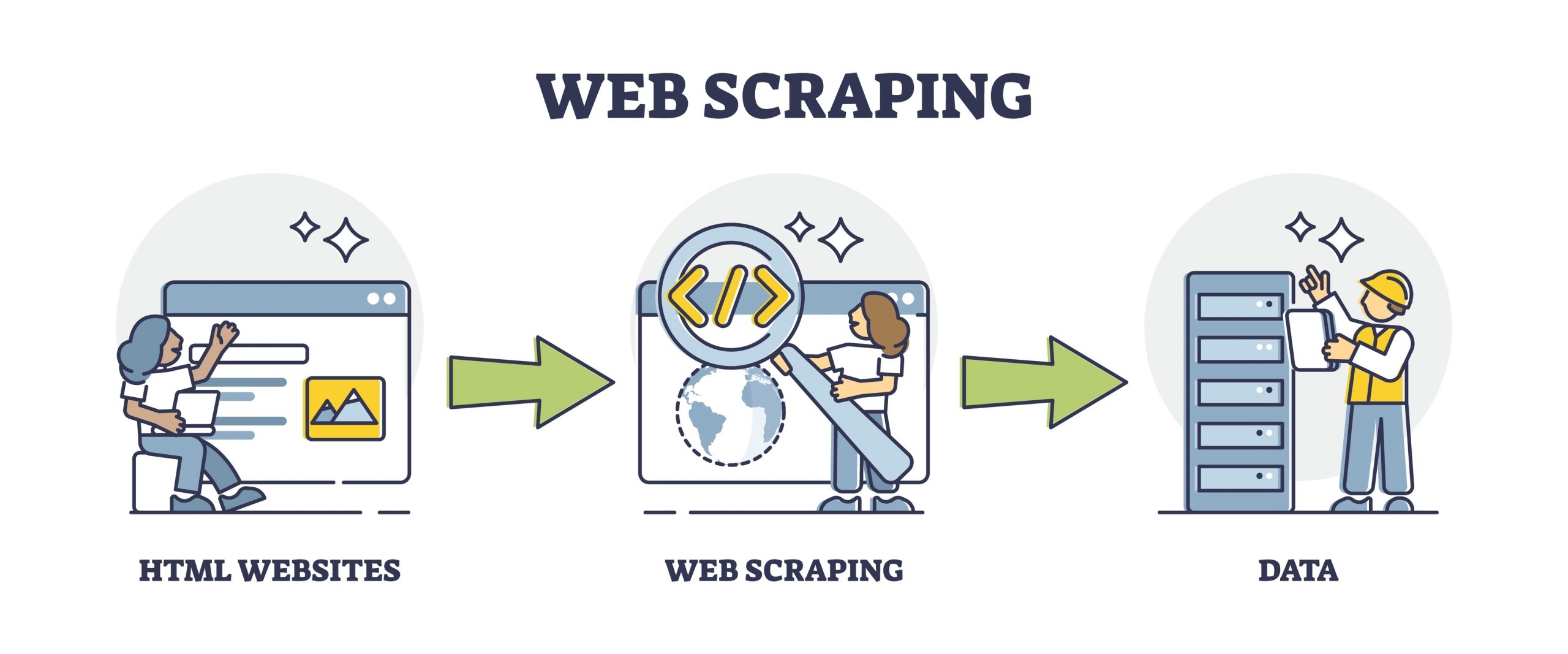
Web Scraping, hay còn được gọi là "rìa web" hoặc "lấy dữ liệu web", là quá trình tự động hóa việc trích xuất thông tin từ trang web. Thông qua việc sử dụng các công cụ và kỹ thuật lập trình, web scraping giúp tự động thu thập dữ liệu từ các trang web và chuyển đổi chúng thành định dạng phù hợp để sử dụng hoặc phân tích.
Quy trình web scraping thường bao gồm việc truy cập trang web, lấy dữ liệu từ HTML hoặc API của trang đó, sau đó chuyển đổi và lưu trữ dữ liệu theo cách mong muốn. Các ứng dụng của web scraping rất đa dạng, từ thu thập dữ liệu thị trường, theo dõi giá cả, đến nghiên cứu dữ liệu và phân tích xu hướng.
Tuy nhiên, cần lưu ý rằng việc sử dụng web scraping cần phải tuân thủ các quy định và chính sách của trang web đó, và một số trang web có thể cấm hoặc hạn chế việc sử dụng web scraping để bảo vệ dữ liệu của họ. Ngoài ra, có những hình thức web scraping độc hại có thể gây nguy hiểm cho cộng đồng trực tuyến và làm ảnh hưởng đến an ninh mạng.
Công cụ Scraper và bot
Công cụ Scraper và Bot là hai khái niệm quan trọng trong lĩnh vực web scraping và tự động hóa các hoạt động trên Internet. Dưới đây là giải thích về cả hai khái niệm này:
Scraper (Rìa):
Ý nghĩa: Scraper là một chương trình máy tính được thiết kế để tự động lấy dữ liệu từ trang web. Scraper thường sử dụng các kỹ thuật như HTTP requests để tải trang web và sau đó phân tích cú pháp HTML của trang để trích xuất thông tin mong muốn.
Công dụng: Công cụ Scraper có thể được sử dụng để thu thập dữ liệu từ nhiều nguồn khác nhau trên Internet, từ thông tin sản phẩm trên trang thương mại điện tử đến dữ liệu thị trường và đánh giá.
Lưu ý: Việc sử dụng Scraper cần phải tuân thủ các quy tắc và chính sách của trang web mà bạn đang rìa, và một số trang có thể cấm hoặc giới hạn việc này.
Bot (Robot):
Ý nghĩa: Bot là một chương trình máy tính tự động thực hiện các nhiệm vụ cụ thể trên Internet mà không cần sự can thiệp của con người. Trong ngữ cảnh web scraping, bot thường được sử dụng để tự động thực hiện các hành động như đăng nhập, điều hướng trang web, và thậm chí là điền các biểu mẫu trực tuyến.
Công dụng: Bot có thể được sử dụng để tăng tốc và tự động hóa các hoạt động trên Internet, từ việc lấy dữ liệu đến thực hiện các tác vụ trên các ứng dụng và trang web.
Lưu ý: Một số bot có thể được sử dụng để mục đích độc hại, như tấn công DDoS hoặc thực hiện các hoạt động spam, vì vậy cần phải có các biện pháp an ninh để ngăn chặn sự lạm dụng.
Sự kết hợp giữa Scraper và Bot giúp tạo ra những công cụ mạnh mẽ có thể tự động hóa quá trình lấy dữ liệu và thực hiện các nhiệm vụ trên Internet, nhưng cũng đặt ra những thách thức về etic và an ninh mạng.
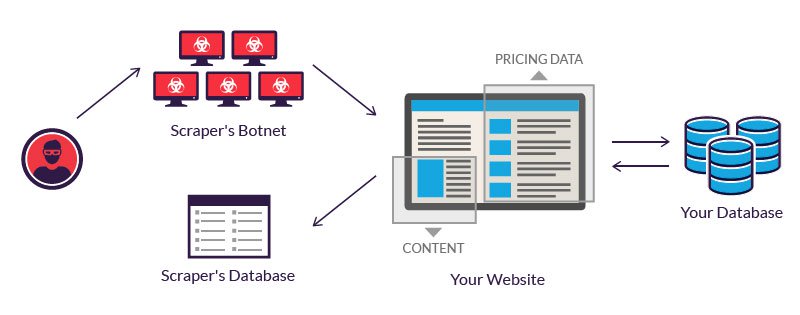
Web scraping độc hại
Web scraping, mặc dù có nhiều ứng dụng hữu ích, nhưng cũng có thể được sử dụng độc hại trong một số tình huống. Dưới đây là một số loại web scraping độc hại:
Price Scraping (Rìa Giá Cả):
Mô tả: Price scraping là việc sử dụng web scraping để tự động lấy dữ liệu về giá cả của sản phẩm hoặc dịch vụ từ các trang web thương mại điện tử hoặc trang web cung cấp thông tin về giá cả.
Tác động độc hại: Các bên có thể sử dụng thông tin về giá cả này để canh bạc hoặc thực hiện các chiến lược cạnh tranh không lành mạnh, gây ảnh hưởng đến cạnh tranh công bằng.
Content Scraping (Rìa Nội Dung):
Mô tả: Content scraping là hành động sử dụng web scraping để lấy nội dung từ trang web, bao gồm cả văn bản, hình ảnh, và video mà không có sự cho phép của chủ sở hữu nội dung.
Tác động độc hại: Việc lấy trộm nội dung có thể dẫn đến việc vi phạm bản quyền, đạo đức nghề nghiệp, và làm suy giảm giá trị nội dung đối với chủ sở hữu.
Email Harvesting (Thu Thập Địa Chỉ Email):
Mô tả: Web scraping có thể được sử dụng để tự động lấy địa chỉ email từ các trang web công khai hoặc diễn đàn trực tuyến.
Tác động độc hại: Địa chỉ email có thể được sử dụng cho mục đích gửi thư rác (spam) hoặc các hoạt động lừa đảo, làm giảm uy tín của người sở hữu email.
Aggressive Scraping (Rìa Tấn Công):
Mô tả: Sử dụng các kỹ thuật web scraping mạnh mẽ và liên tục để tải lượng lớn dữ liệu từ trang web một cách nhanh chóng, có thể gây áp lực lớn lên máy chủ của trang web đó.
Tác động độc hại: Có thể gây tắc nghẽn trang web, làm chậm trải nghiệm người dùng chân thực và làm hỏng cơ sở hạ tầng của trang web.
Lưu ý rằng việc sử dụng web scraping cần phải tuân thủ các quy tắc và chính sách của trang web, và việc sử dụng không đúng cách có thể đặt ra nhiều vấn đề về đạo đức và pháp lý.
Web Scraping hoạt động như thế nào?
Quá trình hoạt động của web scraping bao gồm các bước chính để tự động lấy dữ liệu từ trang web. Dưới đây là mô tả tổng quan về cách web scraping hoạt động:
Xác định Mục Tiêu:
Người sử dụng xác định trang web hoặc trang các dữ liệu cần được thu thập. Điều này có thể là trang thương mại điện tử, trang web tin tức, hoặc bất kỳ trang web nào chứa thông tin cần lấy.
Phân Tích Cấu Trúc Trang Web:
Người sử dụng phân tích cấu trúc của trang web để hiểu cách thông tin được tổ chức trong mã nguồn HTML. Điều này bao gồm việc xác định các thẻ HTML, lớp CSS, hoặc các đặc điểm khác cần thiết để xác định vị trí của dữ liệu.
Gửi Yêu Cầu HTTP:
Một chương trình máy tính hoặc bot gửi yêu cầu HTTP đến máy chủ của trang web để lấy mã nguồn HTML của trang. Điều này có thể thực hiện bằng cách sử dụng thư viện HTTP trong ngôn ngữ lập trình như Python hoặc qua các công cụ chuyên dụng như cURL.
Trích Xuất Dữ Liệu:
Mã nguồn HTML được trích xuất và phân tích để lấy thông tin cần thiết. Các kỹ thuật như XPath hoặc CSS selectors có thể được sử dụng để xác định vị trí của dữ liệu trên trang web.
Chuyển Đổi Dữ Liệu:
Dữ liệu sau khi được trích xuất thường cần được chuyển đổi sang định dạng phù hợp để dễ dàng lưu trữ hoặc phân tích. Điều này có thể bao gồm việc chuyển đổi dữ liệu thành định dạng JSON, CSV, hoặc bất kỳ định dạng nào khác.
Lưu Trữ hoặc Sử Dụng Dữ Liệu:
Dữ liệu sau khi được trích xuất có thể được lưu trữ trong cơ sở dữ liệu hoặc sử dụng trực tiếp để phân tích, hiển thị, hoặc thực hiện các tác vụ khác tùy thuộc vào mục đích của người sử dụng.
Lưu ý rằng việc sử dụng web scraping cần phải tuân thủ các quy tắc và chính sách của trang web mà bạn đang rìa, và việc sử dụng không đúng cách có thể gây ra vấn đề về etic và pháp lý.
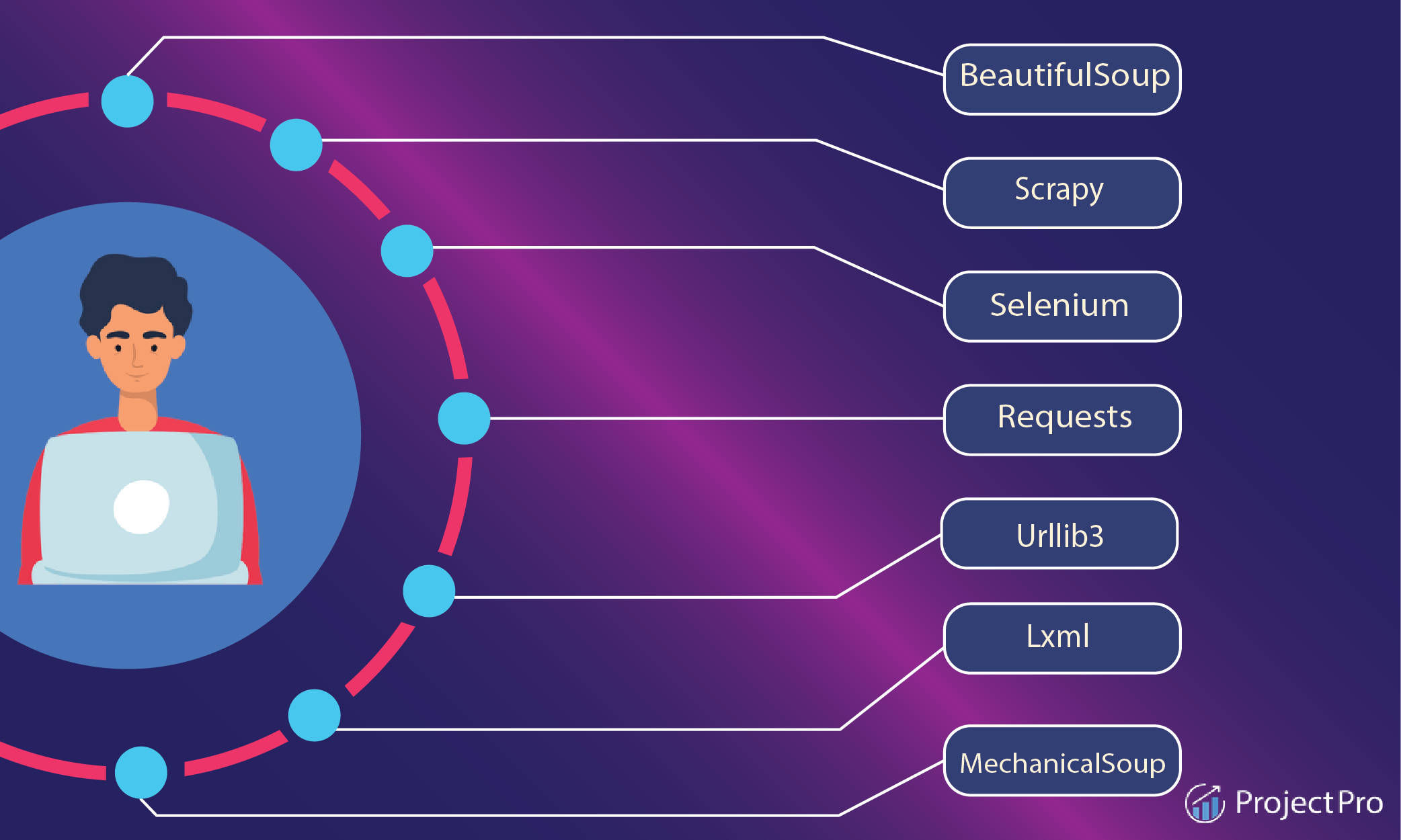
Các loại Web Scraper
Web scraper có thể được phân loại dựa trên một số tiêu chí khác nhau, bao gồm cả cách chúng được xây dựng, giao diện người dùng, cách triển khai, và nơi lưu trữ dữ liệu. Dưới đây là phân loại theo một số tiêu chí quan trọng:
Self-built or Pre-built (Tự xây dựng hoặc Sẵn có):
Self-built (Tự xây dựng): Web scraper được xây dựng từ đầu bởi người sử dụng, sử dụng ngôn ngữ lập trình như Python, Java, hoặc Node.js. Điều này đòi hỏi kiến thức kỹ thuật và khả năng lập trình.
Pre-built (Sẵn có): Web scraper đã được xây dựng trước và cung cấp sẵn cho người sử dụng, thường thông qua các thư viện, framework hoặc công cụ như Scrapy, BeautifulSoup (Python), hoặc Puppeteer (JavaScript).
Browser Extension vs Software:
Browser Extension (Tiện Ích Trình Duyệt): Các web scraper có thể là tiện ích mở rộng cho trình duyệt, cung cấp tính năng tự động lấy dữ liệu trực tiếp từ trang web mà người sử dụng đang xem.
Software (Phần Mềm): Web scraper có thể là các ứng dụng độc lập được cài đặt trên máy tính, có khả năng hoạt động tách biệt với trình duyệt.
User Interface (Giao Diện Người Dùng):
With UI (Có Giao Diện Người Dùng): Một số web scraper cung cấp giao diện người dùng đồ họa để người sử dụng có thể cấu hình và sử dụng mà không cần kiến thức lập trình sâu.
Without UI (Không Có Giao Diện Người Dùng): Các web scraper chỉ có thể được cấu hình và sử dụng thông qua mã lệnh, yêu cầu người sử dụng có kiến thức vững về lập trình.
Cloud vs Local:
Cloud-based (Dựa trên Đám Mây): Các dịch vụ web scraping được triển khai trên nền tảng đám mây, giúp xử lý lớn và lưu trữ dữ liệu một cách linh hoạt và thuận tiện.
Local (Trên Máy): Các web scraper hoạt động trên máy tính cục bộ, thường yêu cầu người sử dụng duy trì và quản lý môi trường cài đặt.
Sự lựa chọn giữa các loại web scraper này thường phụ thuộc vào mục đích cụ thể và kỹ năng kỹ thuật của người sử dụng.
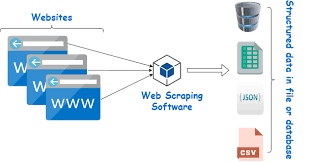
Web Scraper dùng để làm gì?
Web scraper được sử dụng cho nhiều mục đích khác nhau, đặc biệt là trong lĩnh vực thu thập dữ liệu từ Internet. Dưới đây là một số mục đích phổ biến mà web scraper được áp dụng:
Thu Thập Dữ Liệu Thị Trường:
Web scraper có thể thu thập thông tin về giá cả sản phẩm, đánh giá, và xu hướng thị trường từ các trang web thương mại điện tử để phục vụ nghiên cứu thị trường và đánh giá cạnh tranh.
Nghiên Cứu và Phân Tích:
Dữ liệu từ các trang web tin tức, diễn đàn, blog, hay trang web chính phủ có thể được thu thập để phục vụ nghiên cứu và phân tích xu hướng, ý kiến cộng đồng, và thông tin liên quan.
Săn Tin Tức và Cập Nhật:
Web scraper có thể giúp tự động lấy thông tin mới từ các trang web tin tức, giúp người dùng theo dõi các sự kiện quan trọng và cập nhật nhanh chóng.
Thu Thập Dữ Liệu Về Sản Phẩm và Dịch Vụ:
Trong lĩnh vực thương mại điện tử, web scraper được sử dụng để thu thập thông tin về sản phẩm và dịch vụ từ các trang web bán lẻ, giúp doanh nghiệp hiểu rõ hơn về thị trường và đối thủ cạnh tranh.
Quảng Cáo và Tiếp Thị Trực Tuyến:
Dữ liệu về xu hướng, ý kiến khách hàng, và thông tin đối thủ có thể giúp doanh nghiệp xây dựng chiến lược quảng cáo và tiếp thị trực tuyến hiệu quả hơn.
Kiểm Tra và Theo Dõi Giá Cả:
Web scraper thường được sử dụng để kiểm tra và theo dõi giá cả sản phẩm và dịch vụ trực tuyến, giúp người dùng tìm kiếm cơ hội mua sắm và so sánh giá.
Tổng Hợp Dữ Liệu:
Web scraper có thể giúp tổng hợp thông tin từ nhiều nguồn khác nhau để tạo ra dữ liệu đa nguồn, hỗ trợ quá trình ra quyết định.
Tạo Nội Dung Tự Động:
Dữ liệu từ web scraper có thể được sử dụng để tạo nội dung tự động cho các trang web, blog, hoặc ứng dụng, giúp tiết kiệm thời gian và công sức.
Tùy thuộc vào mục đích cụ thể, web scraper có thể đóng vai trò quan trọng trong việc tự động hóa quá trình thu thập và xử lý dữ liệu từ Internet.
Kết luận
Web scraping, hay còn được gọi là "rìa web", là một công nghệ mạnh mẽ giúp tự động lấy dữ liệu từ Internet, mang lại nhiều ứng dụng quan trọng trong nghiên cứu thị trường, đánh giá cạnh tranh, và theo dõi xu hướng. Tuy nhiên, sự mạnh mẽ của web scraping cũng đặt ra những thách thức đối với việc duy trì đạo đức và an ninh mạng, đặc biệt là khi sử dụng các kỹ thuật độc hại như price scraping và content scraping. Việc sử dụng web scraping đòi hỏi sự chú ý đến các quy định của trang web, tôn trọng quyền riêng tư, và đảm bảo an ninh thông tin. Tùy thuộc vào mục đích sử dụng, người dùng cần lựa chọn giữa các loại web scraper khác nhau, từ tự xây dựng đến sẵn có, từ tiện ích trình duyệt đến phần mềm độc lập. Việc hiểu rõ về cách web scraping hoạt động và lựa chọn đúng loại công cụ là quan trọng để đảm bảo việc sử dụng mạnh mẽ nhưng an toàn và đạo đức.
Bài liên quan